
【瑞数】维普期刊搜索接口逆向总结_2_获取Cookie
编辑前文回顾
在【瑞数】维普期刊JS逆向详细流程及4000字爬虫总结(1)一文中,成功拿到了搜索接口的签名。
本文主要探究cookie的获取。
- 接口签名的生成与获取
- cookie的生成与获取
- 基于浏览器环境的爬虫如何部署?
- 关于本次瑞数解密的总结
提出问题
一提到cookie的获取,第一想法就是简单。通常的流程就是请求一下网页,然后在响应中提取cookie即可。
但是在维普期刊这个例子里,并不是这样。先来了解在调试中我所遇到的实际问题。
然后在后文中,我们一一来解决这些问题。
问题1:Cookie从何而来?
问题描述
在上文中,我们是从浏览器中直接复制的cookie
那么这个cookie从哪来?
通过抓包可以知道cookie中name为GW1gelwM5YZuS的值是服务端给的(在第二个问题中有解释)。
在返回的所有响应头中,没有发现设置GW1gelwM5YZuT的值,那么可以断定这是在本地生成的。
hook查看GW1gelwM5YZuT何时生成
使用hook函数在设置cookie时进入debugger状态
(function(){
var org = document.cookie.__lookupSetter__('cookie');
document.__defineSetter__("cookie",function(cookie){
if(cookie.indexOf('GW1gelwM5YZuT')>-1){
debugger;
}
org = cookie;
return cookie;
});
document.__defineGetter__("cookie",function(){return org;});
})();
hook流程
- 找到第一次加载的JS代码或JS文件,在第一行代码上断点;
- 调式进入暂停后,在console键入hook函数;
- 放行
加载的第一个js文件是leE4DklasHMb.f22c526.js,在第一行打下断点,然后刷新页面

进入断点后,在console键入hook代码,按F8放行
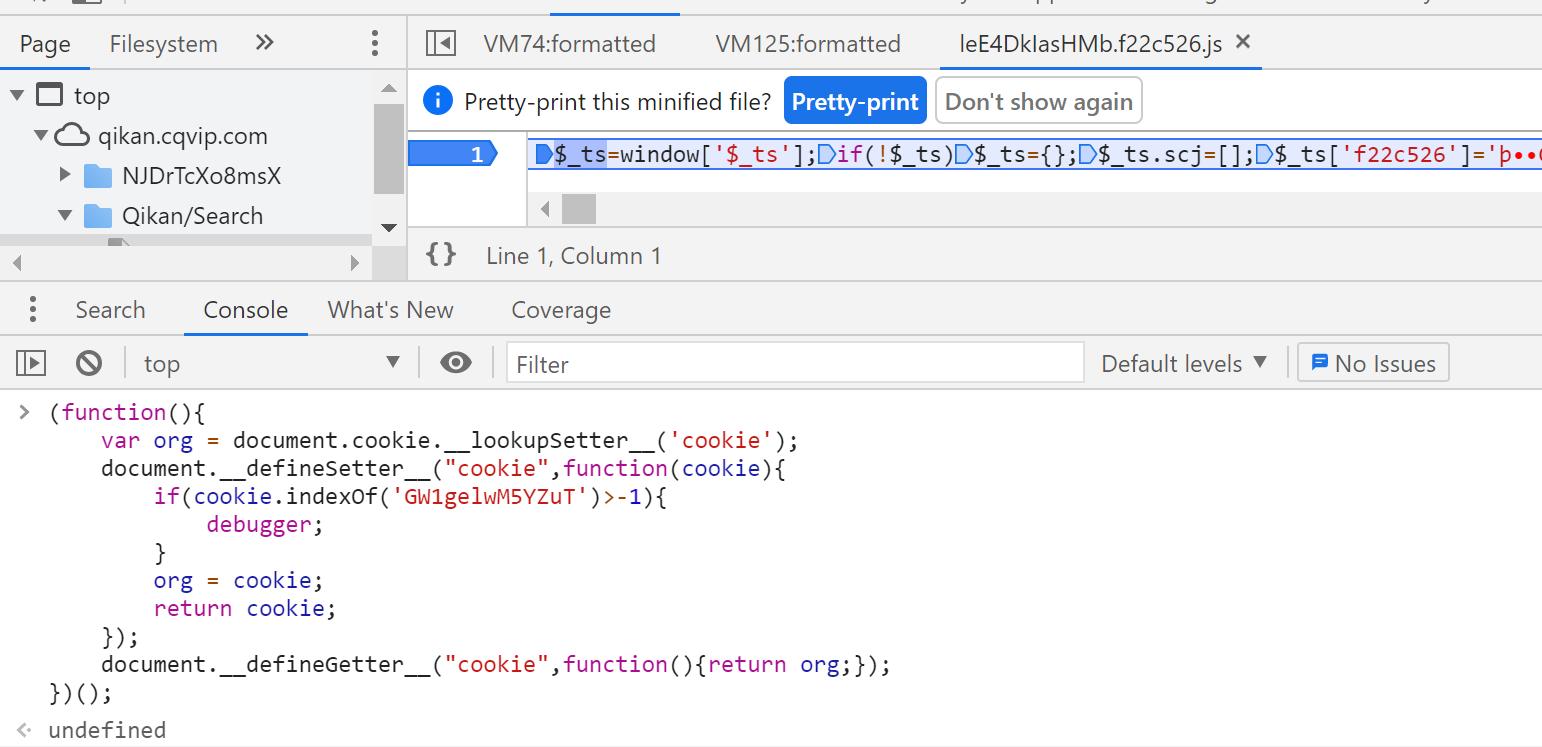
GW1gelwM5YZuT被设置,成功暂停
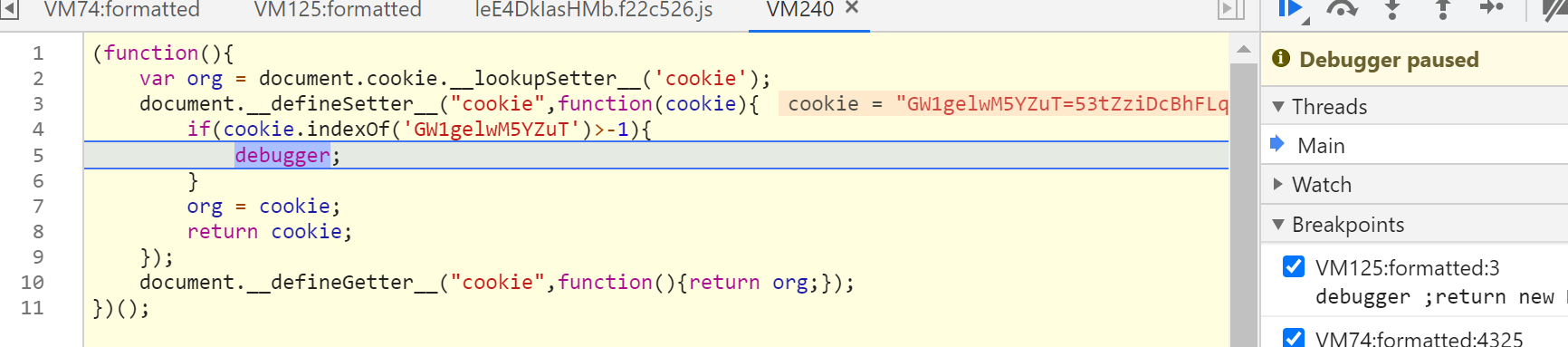
查看调用栈,这里的_$bs就是GW1gelwM5YZuT的值,是从调用方传过来的,继续向上回溯查看。
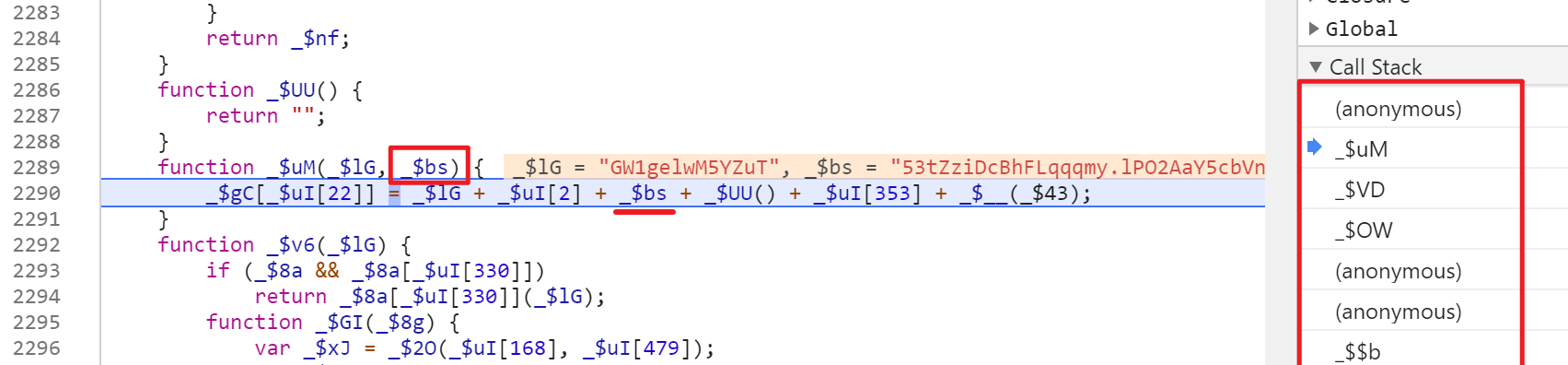
然后找到这行代码xx(773, 1),如果继续向上找,这是在首次允许整个签名代码时执行的,且只会调用一次。
换句话说,这行代码是在搜索页面加载时执行的。

Tips:如果上面的调试过程,超过了40秒左右,这次放行又会立即暂停到我们的hook函数内。
继续往上回溯,可以看到这次是_$VD(733, 10),这和刚才的xx(773, 1)有所不同。
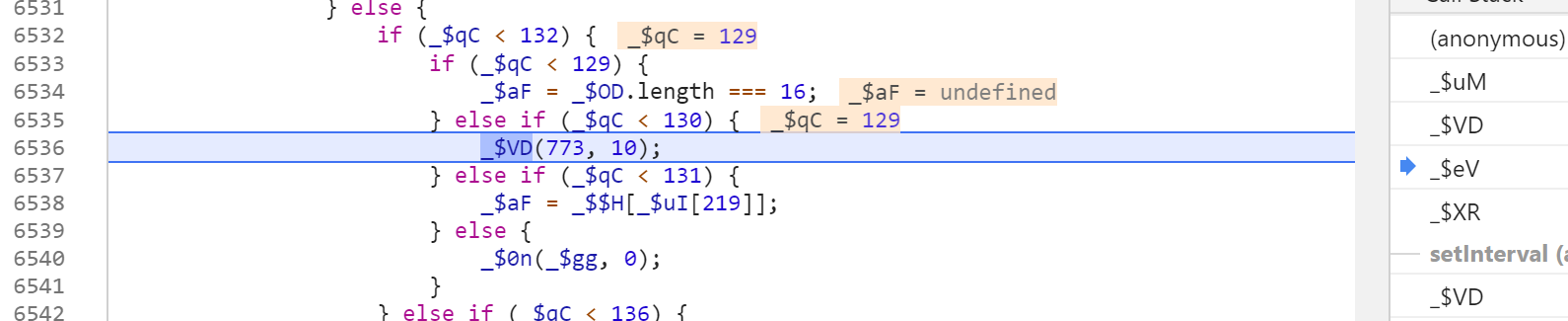
继续向上向上查看调用栈,可以看到类似代码,这是设置了定时器。作用就是每隔50秒,调用一次_$XR方法,即设置一次GW1gelwM5YZuT的值。
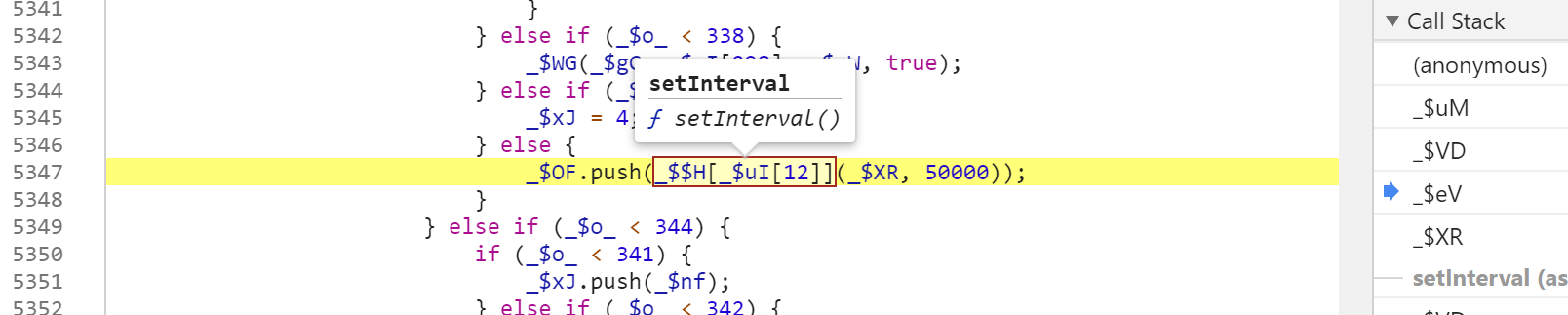
以上是比较容易发现的触发方式,另外还有事件可以触发GW1gelwM5YZuT的生成,有兴趣可以多调试看看。
- 页面加载事件;
- 定时器事件;
- 鼠标点击事件;
问题2:搜索页面不匹配
问题描述
在上文中,需要拿到搜索页面的源代码才能进行代码注入。
之前是通过手动复制的方式获取,现在则是需要通过Python发送请求拿到搜索页面。
当我直接请求搜索页面,返回的代码如下:
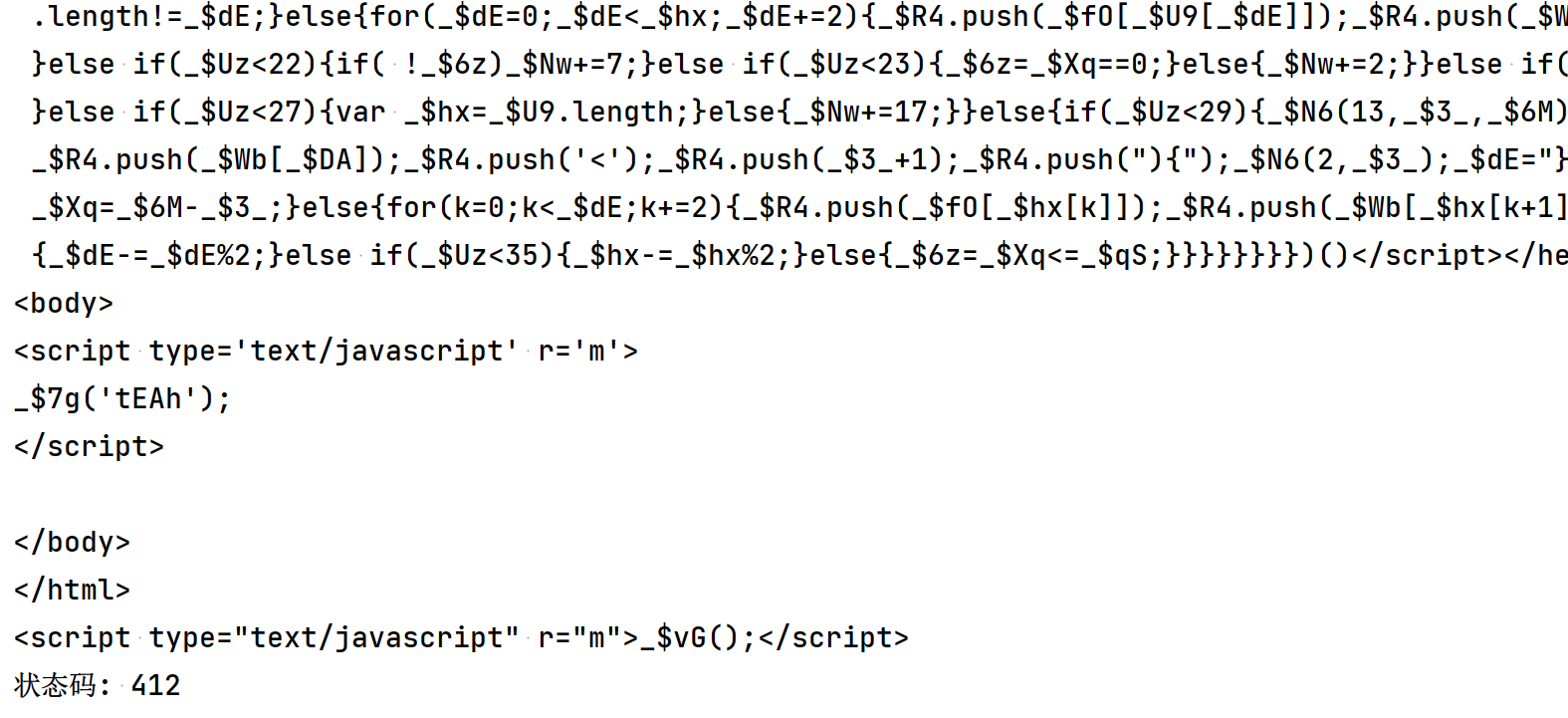
返回的结果明显和之前手动复制的不同。
第一状态码不对,正常请求应该是返回 200
第二内容不对,这次请求返回的html,虽然也有一段混淆的JS,但是,body标签内几乎没有什么代码。
抓包分析
打开抓包工具(本文使用的是Fiddler),并在浏览器匿名窗口访问搜索主页。

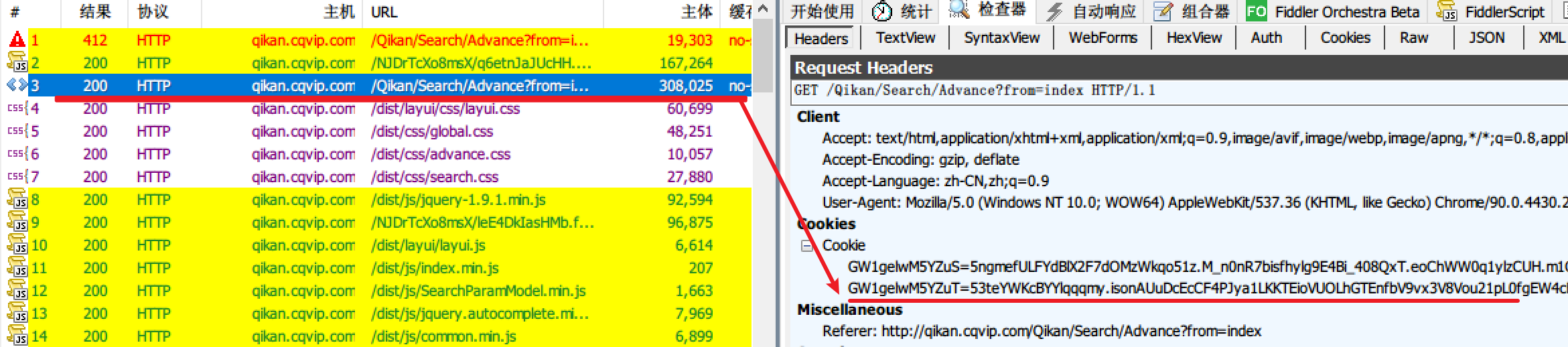
第一次请求,状态码确实是412。
请求搜索页面的流程:
- 请求搜索页面,返回html页面,状态码为412;
- html中引入了JS文件,则请求这个JS文件;
- 再次请求搜索页面,请求成功;
接下来,我们分析如何才能获取到正确的搜索页面。
第一次请求并不是一无是处,首先为浏览器设置了cookie,这个就是Gw1gelwM5YZuS的来源。

然后html页面中引入了一个JS文件
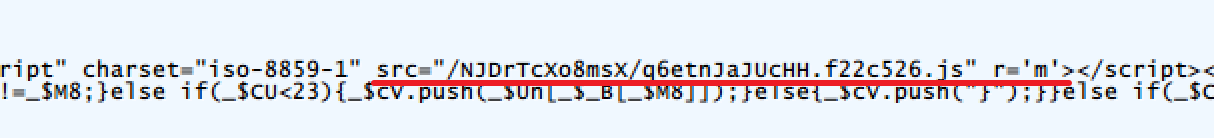
这一点和上文搜索接口签名一致,共同的特点就是引入JS文件赋值,通过html中的JS代码还原字符串代码,然后加载代码并执行
这个JS文件暂时放下不管,先分析第二次搜索页面请求。
可以看到,第二次请求搜索页面时,cookie多了一个GW1gelwM5YZut,所以首次请求搜索页面,其作用就是生成可访问搜索页面的cookie
自问自答环节
Q:既然cookie都已经生成了,那么带上这个cookie在python中发送请求,可以吗?
A:不行,经过多次调试,这个Cookie仅能用于访问一次搜索页面。
Q:访问搜索页面的cookie可以用于搜索接口吗?
A:不行
关于上面问题与回答,是通过大量调试和踩坑"猜"出来。
如何获取“页面Cookie”
第一个问题中的Cookie是用于搜索接口,这次我们需要获取的Cookie则是访问搜索页面的**“钥匙”**。
为了区分,这个Cookie称为页面Cookie。
页面Cookie关键值两个:GW1gelwM5YZuS、GW1gelwM5YZuT
**Tips:**我稍稍看了下药监局的瑞数,这个Cookie也是有特点的,会以xxxxS和 xxxxT命名。

改改称呼,方便一点
以S结尾的,称作s_cookie
以T结尾的,称作t_cookie
ok,s_cookie在上一节的抓包分析中得知,这个值由服务端提供,除此之外s_cookie可用于搜索接口的请求,这个可以简单调试看看,多次请求s_cooie一直是不变的,t_cookie则是频繁变化。
接下来就让我们一起来解密t_cookie,这也是本章的核心内容。
打开审查工具,刷新页面,开始调试,发现第一个请求就是状态码200,但是我们需要的是状态码为412的请求。
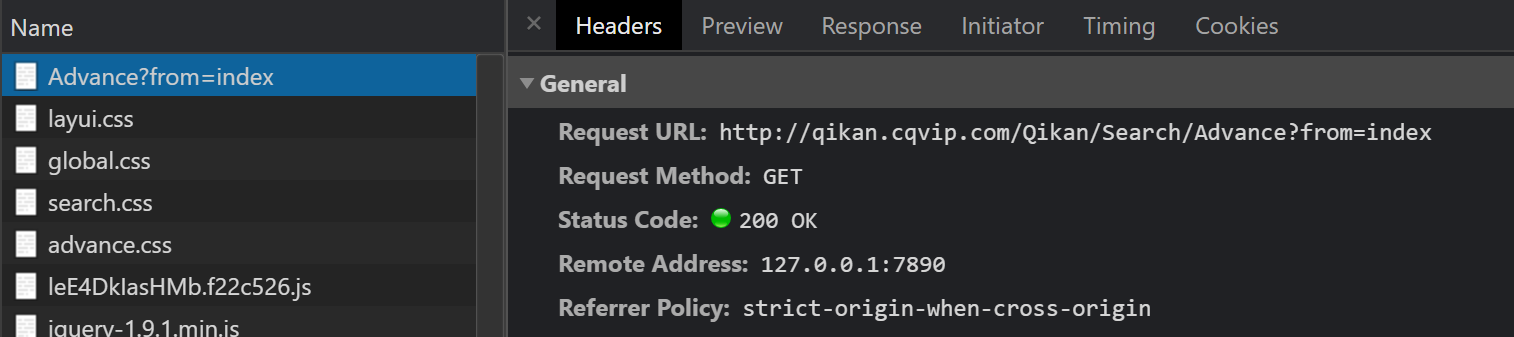
这是因为跳转导致(这就是故意为之)
我先讲一讲调试思路。
使用Fiddler拦截响应,并只允许通过第一次页面的响应和JS文件响应。
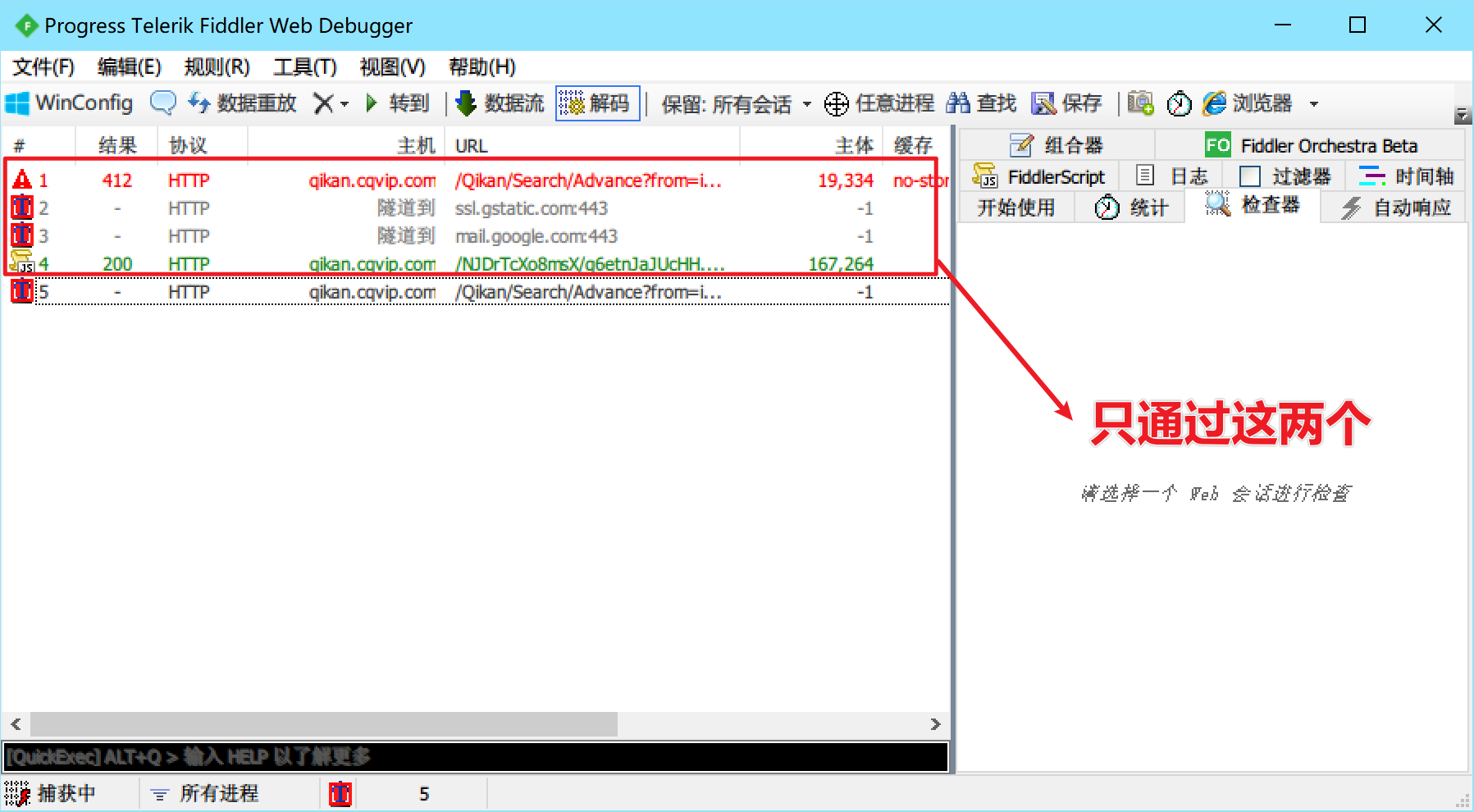
这个时候打开审查工具,查看Application中的Cookies,可以看到“新鲜出炉”的Cookie。

拿出来测试看看,没问题。

验证页面Cookie是否可用的代码如下
# -*- coding: utf-8 -*-
"""
Created on 2021/5/25 15:25
---------
@summary:
---------
@author: mkdir700
@email: mkdir700@gmail.com
"""
import requests
session = requests.session()
s = input("请输入GW1gelwM5YZuS的值:\r\n")
value = input("请输入GW1gelwM5YZuT的值:\r\n")
session.headers = {
"Host": "qikan.cqvip.com",
"Connection": "keep-alive",
"sec-ch-ua": '" Not A;Brand";v="99", "Chromium";v="90", "Google Chrome";v="90"',
"sec-ch-ua-mobile": "?0",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Cookie": "GW1gelwM5YZuS={}; GW1gelwM5YZuT={}".format(s, value),
"Sec-Fetch-Site": "none",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-User": "?1",
"Sec-Fetch-Dest": "document",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
}
resp = session.get("http://qikan.cqvip.com/Qikan/Search/Advance?from=index")
# print(resp.text)
# print(resp.request.headers)
print(resp.status_code)
如果用这个页面Cookie再请求一次就会失败

页面Cookie的自动化获取
我的思路如下:
- 依赖浏览器环境,将两个Cookie生成
- 读取Cookie即可
这当中存在一个问题,那就是我没法控制请求的次数。
正常的流程是,浏览器打开页面,会让能加载的都加载,能运行的都运行。
而我们的要求是加载一个html页面和一个JS文件,为了避免页面Cookie被使用而导致失效,此时需要停止后续的所有请求。
手动获取Cookie是借助了抓包工具拦截响应的功能。那么有没有什么办法达到同样的效果呢?
我首先想到的是mitmproxy(中间人),作为中间人,我们可以修改内容,也有权决定请求与响应的去留。
使用mitmproxy应该是个比较快速的办法,然后我嫌麻烦(其实没有多麻烦, 哈哈哈),放弃了。
我选择的方式是浏览器插件。
我将hook函数封装为浏览器插件,只要检测到t_cookie生成后,就将其赋值给全局变量。
然后使用window.stop停止整个网页的加载,保证页面Cookie不会被使用。
inject.jshook函数代码
var code = function () {
var org = document.cookie.__lookupSetter__('cookie');
document.__defineSetter__("cookie", function (cookie) {
if (cookie.indexOf('GW1gelwM5YZuT') > -1) {
var t = cookie.split("=")[1].split(";")[0];
window.t_cookie = t;
console.log(t);
window.stop();
}
return org;
});
document.__defineGetter__("cookie", function () {
return org;
});
}
var script = document.createElement('script');
script.textContent = '(' + code + ')()';
(document.head || document.documentElement).appendChild(script);
script.parentNode.removeChild(script);
manifest.json
{
"name": "Injection",
"version": "2.0",
"description": "Cookie钩子",
"manifest_version": 2,
"content_scripts": [
{
"matches": [
"<all_urls>"
],
"js": [
"inject.js"
],
"all_frames": true,
"permissions": [
"tabs"
],
"run_at": "document_start"
}
]
}
这两个文件在同一目录下,制作chrome插件的教程,网上搜一搜就行,非常简单。
实现效果

获取页面Cookie代码,插件inject文件夹与这个py文件在同一目录
# -*- coding: utf-8 -*-
"""
Created on 2021/5/25 19:22
---------
@summary:
---------
@author: mkdir700
@email: mkdir700@gmail.com
"""
import asyncio
import os
import time
from pyppeteer import launch
from pyppeteer_stealth import stealth
async def close_page(browser):
await browser.close()
async def start():
# 插件文件夹路径
chrome_extension = os.path.join(os.path.abspath('./'), 'inject')
browser = await launch(
{
'headless': False,
'userDataDir': './userDataDir',
'args': [
'--no-sandbox',
'--load-extension={}'.format(chrome_extension),
'--disable-extensions-except={}'.format(chrome_extension),
'--window-size=0,0'
]
}
)
page = await browser.newPage()
await page.setViewport(viewport={'width': 1000, 'height': 800})
await stealth(page)
await page.goto("http://qikan.cqvip.com/Qikan/Search/Advance?from=index")
time.sleep(0.5)
t = await page.evaluate("() => {return t_cookie;}")
cookies = await page.cookies()
s = None
for c in cookies:
if "GW1gelwM5YZuS" == c['name']:
s = c['value']
data = {'s': s, 't': t}
# print(data)
await browser.close()
return data
def get_cookies():
data = asyncio.get_event_loop().run_until_complete(start())
return data
if __name__ == '__main__':
print(get_cookies())
总结
cookie的获取到这里就算结束了,cookie分为两种类型,一种用于搜索页面,另一种是用于搜索接口。
搜索接口的cookie可用于页面,页面的cookie不能用于搜索
cookie中的核心关键是这个t_cookie,这是在本机生成的。关于他详细的生成逻辑,我没有再分析。
我只知道,服务端返回的s_cookie影响着t_cookie的值,如果有大佬知道其中的生成逻辑,求告知。
这里在额外说下,搜索页面与cookie存在某种绑定关系,比如,拿出A浏览器返回的搜索页面源代码,复制B浏览器中的cookie,这样请求搜索接口将会失败。
结合第一篇文章,重新梳理整个执行流程如下:
- 首次访问搜索页面(状态码412),被设置
s_cookie; - 加载搜索页面及JS代码,被设置
t_cookie; - 跳转,再次请求搜索页面(状态码200);
- 加载页面及JS代码,重设
t_cookie(可用于搜索接口) - 根据接口地址生成签名;
- 带上
s_cookie、t_cookie、签名和请求参数,即可请求成功。
- 0
- 0
-
分享